1.Register an account
Register a Scrapingbypass API account, click Register
Register a Scrapingbypass proxy account, click Register
Scrapingbypass accounts are interoperable. You only need to register for one of them. Log in to the backend within 30 days after registration, click the "Activity" button, and receive a novice trial gift pack of points and traffic.
2.Code Generator
Enter your request address into: Code Generator and test whether it is completed Bypass Cloudflare verification.
The V1 version comes with a Rotating Proxy pool. If it is accessible, there is no need to configure an Proxy;
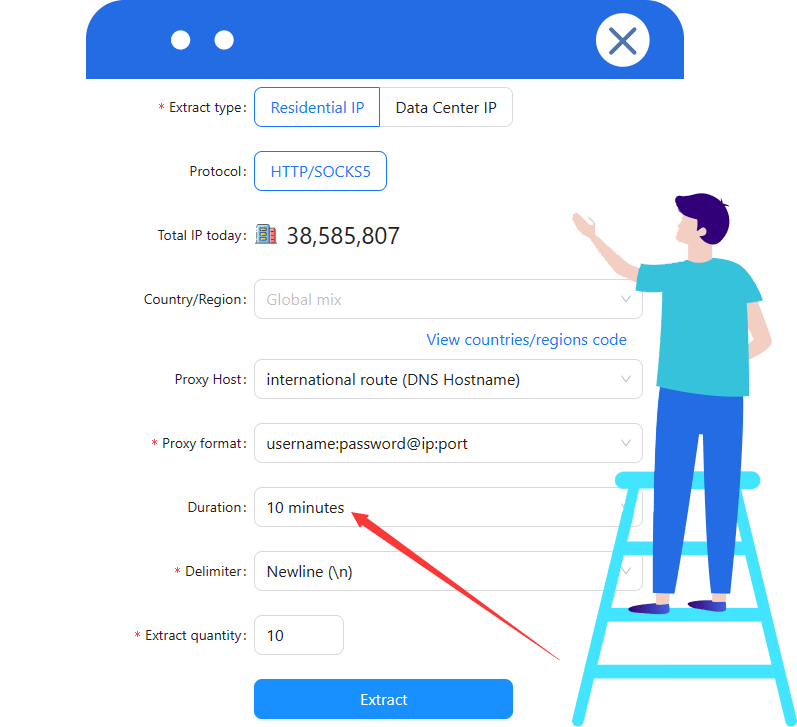
The V2 version must be configured with a fixed IP or a time-effective IP, such as Cloudbypass Rotating Proxy. Set a time limit of more than 10 minutes. (pictured)
For technical assistance, please view the API documentation or Contact Customer Service for support.
3.Integrate Scrapingbypass API
Integrate the Scrapingbypass API code into your own code function module, complete the final debugging and use it.